
AWS Recipe: Build an Asynchronous Serverless Task API
In this article, you will learn how to build an asynchronous serverless task API from scratch on AWS using Lambda, DynamoDB, API Gateway, SQS, and SNS. The Lambda functions will be implemented in Python, and the REST API will use the FastAPI framework. The entire application will be deployed using AWS SAM.
Introduction
This article will guide you through the process of building an asynchronous serverless task API on AWS. With complete code examples, you will learn how to:
- Run FastAPI in a Lambda function behind an API Gateway using DynamoDB for storage.
- Using DynamoDB streams with filters together with a Lambda function to publish events to SNS.
- Implementing a fan-out pattern with SNS and SQS to distribute tasks to different handlers.
- Using Systems Manager Parameter Store to share variables between CloudFormation stacks.
We will first build a stack that includes an API that allows clients to create and list tasks. This API will be deployed to AWS Lambda behind a HTTP API Gateway. The application will store tasks in DynamoDB, and whenever a new task is created it will be sent via a DynamoDB Stream to another Lambda that will publish the task to SNS.
In another stack, we will create handlers where each handler will be responsible for processing a specific type of task. Each handler will comprise of an SQS queue that will receive tasks from SNS, and a Lambda function that will process the task and report the task status back to the REST API.
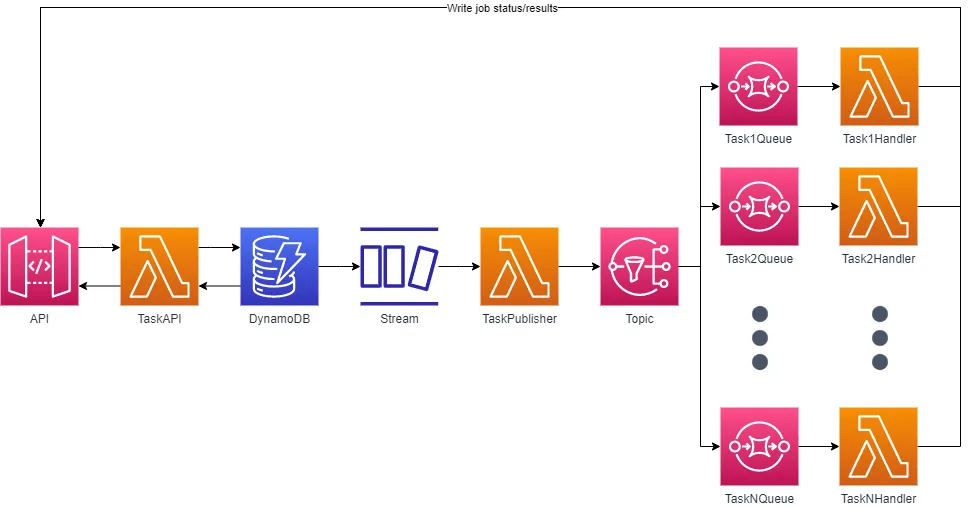
Recipe ingredients
- API Gateway
- Lambda
- DynamoDB
- DynamoDB Stream
- SNS
- SQS
- FastAPI
Requirements
To follow along in this article, you will need:
- Python
- AWS SAM CLI
Build the API stack
Let’s begin by setting up everything required on the API side of the architecture. The API stack will include the following:
- An API Gateway to act as an entry point for the API.
- A Lambda Function running FastAPI for the backend logic.
- A DynamoDB Table for storing data about tasks.
- A DynamoDB Stream that records changes made to the table.
- A Lambda Function that is invoked whenever a new task is created, via the stream.
- An SNS Topic, on which new tasks are published for further processing by handlers.
1. Create folder structure and required SAM files
To make it easier to understand in which file everything below should go into, this is how the API stack directory will look when you are finished with this section.
api-stack/ api-function/ requirements.txt app/ __init__.py dynamo.py models.py publish-function requirements.txt app/ __init__.py template.yml samconfig.tomlStart by creating and adding the following to the api-stack/template.yml file.
AWSTemplateFormatVersion: '2010-09-09'Transform: AWS::Serverless-2016-10-31Description: Task API
Resources:To make SAM deployment easier and avoid parameters to the sam deploy command, add the following to api-stack/sam-config.toml.
version = 0.1
[default.global.parameters]stack_name = "TaskAPI" # Or choose your own stack name
[default.deploy][default.deploy.parameters]capabilities = "CAPABILITY_IAM"s3_bucket = "BUCKET_NAME" # A bucket your credentials have access tos3_prefix = "task-api" # The prefix that will be used for your s3 assetsregion = "eu-west-1" # Change to your preferred region2. DynamoDB Table
To start off, we will create a table that will store all of our tasks. In this example we will keep the table rather simple, and use only a Primary Key named id.
If you, for example, want to have tasks scoped to e.g. a user, an application, an organization, or some other kind of entity in your systems, you could opt for a schema where you use the entity ID (such as User ID) as the Primary Key and the Task ID as the Sort Key. But for now, let’s keep it simple and continue with just using the Task ID as Primary Key.
We will use the CloudFormation resource AWS::DynamoDB::Table to define the table, since AWS::Serverless::SimpleTable does not support advanced features such as streams.
In Resources in the SAM template, add the following.
Table: Type: AWS::DynamoDB::Table Properties: TableName: tasks AttributeDefinitions: - AttributeName: id AttributeType: S KeySchema: - AttributeName: id KeyType: HASH ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1Tip
I’ve used the minimum provisioned throughput for testing purposes. Feel free to modify it to your needs, or change it if you want to use on-demand billing.
Feel free to deploy your SAM application after every step to verify that everything works. To do so, from the api-stack directory, first build the application with sam build and deploy it with sam deploy.
3. API Gateway
To front our API we will use API Gateway. More specifically, we will use a HTTP API since it is both cheaper and we do not need the more advanced features of a REST API.
Tip
For now, we will not use any features such as Authorization, CORS, or any other advanced features of an API Gateway. Authorization is mentioned in the potential improvements section.
In Resources in the SAM template, add the following.
Api: Type: AWS::Serverless::HttpApi
ApiUrlParameter: Type: AWS::SSM::Parameter Properties: Name: '/tasks/api_url' Type: String Value: !Sub 'https://${Api}.execute-api.${AWS::Region}.${AWS::URLSuffix}'The resource ApiUrlParameter will output the URL of the API Gateway to AWS Systems Manager Parameter Store. This will be used as input to the task handler stack(s).
To easily find the auto-generated API URL, you can take advantage of CloudFormation Outputs. Add the following to the SAM template. Remember, Outputs is a top-level key.
Outputs: ApiUrl: Description: URL of the Task API Value: Fn::Sub: 'https://${Api}.execute-api.${AWS::Region}.${AWS::URLSuffix}'The next time you run sam deploy, you should see the URL in the output.
4. Lambda API
Finally it is time to write some actual code and we will be using Python for this. We will use the FastAPI framwork to build our API, and use an adapter library called Mangum to make FastAPI play nice inside a Lambda function.
SAM Template
We need to define our Lambda function in the SAM template. Add the following resource.
ApiFunction: Type: AWS::Serverless::Function Properties: FunctionName: 'TaskAPI' MemorySize: 128 CodeUri: api-function Handler: app.handler Runtime: python3.9 Policies: - DynamoDBCrudPolicy: TableName: !Ref Table Environment: Variables: TABLE_NAME: !Ref Table Events: DefaultEndpoint: Type: HttpApi Properties: ApiId: !Ref ApiThe above template references the Table resource created before to add the table name as an environment variable, as well as adding an IAM policy to the Lambda execution role that allows it to perform CRUD operations on the DynamoDB table. We also add the API Gateway created earlier as an event source.
Boilerplate
First let’s create a requirements.txt file in the api-stack/api-function directory. This should include the following packages.
mangumfastapiboto3pydanticThen, in the the api-stack/api-function/app/__init__.py file, add the following.
from fastapi import FastAPI, HTTPExceptionfrom mangum import Mangum
app = FastAPI()handler = Mangum(app)HTTPException will be used later on, so might aswell add it in now.
Routes
We will implement the following routes:
- GET /tasks: Returns a list of all tasks.
- GET /tasks/{id}: Returns a task with the given ID.
- POST /tasks: Creates a new task.
- PATCH /tasks/{id}: Updates the status of a task with the given ID.
GET /tasks/{id}
Let’s start with implementing the Get /tasks/{id} endpoint. First, in the api-stack/api-function/app/dynamo.py file, add the following.
import osimport boto3
table = boto3.resource("dynamodb").Table(os.environ["TABLE_NAME"])
class Error(Exception): pass
class TaskNotFoundError(Error): pass
def get_task(task_id: str) -> dict: res = table.get_item( Key={ "id": task_id, }, )
item = res.get("Item") if not item: raise TaskNotFoundError
return itemHere we use the boto3 resource client to call the GetItem API with the task_id as the Primary Key. If the task is not found, we raise an error, otherwise we return the task data. We do not filter the data here, this is handled by FastAPI response models as you will see soon.
Before creating our route logic, let’s create a response model that will define what data is returned by the API when a task is retrieved. We will use pydantic to declare our models
In api-stack/api-function/app/models.py, add the following.
from pydantic import BaseModelfrom typing import Literal
task_types = Literal["TASK1", "TASK2", "TASK3"]status_types = Literal["CREATED", "IN_PROGRESS", "COMPLETED", "FAILED"]
class TaskResponse(BaseModel): id: str task_type: task_types status: status_types status_msg: str = "" created_time: int = None updated_time: int = NoneNow, let’s create the route logic. In api-stack/api-function/app/__init__.py, add the following.
from . import models, dynamo
...
@app.get("/tasks/{task_id}", response_model=models.TaskResponse)def get_task(task_id: str): try: return dynamo.get_task(task_id) except dynamo.TaskNotFoundError: raise HTTPException(status_code=404, detail="Task not found")Let’s deploy what we have so far and see if it works. Run sam build and sam deploy.
If you haven’t used FastAPI before this might come as a surprise, but fire up your favourite browser and navigate to https://YOUR_API_URL/docs. The URL should be listed in the output of sam deploy.
FastAPI comes with built-in support for generating and serving documentation for your API using Swagger. Try your new route from the Swagger UI or with something like curl.
$ curl https://YOUR_API_URL/tasks/12345{ "detail": "Task not found"}Obviously, no tasks exist yet since we haven’t created any yet. Let’s change that and implement the create route.
POST /tasks
It is time to implement the logic for creating tasks. First, we need to decide what kind of input the user should include in the request. We want to support different kinds of tasks, so we will need to include a task_type field in the request. Different tasks might require different payloads, so let’s add a data field in the request which accepts generic json.
When a task is created, the response we will send the user will include the task ID.
Add the following models to api-stack/api-function/app/models.py.
class CreatePayload(BaseModel): task_type: task_types data: dict
class CreateResponse(BaseModel): id: strWhen creating a task, we want to generate an ID for the task. We can use the uuid library to generate a random UUID. We will also add the current timestamp in the attribute created_time. And finally, to avoid handling json in payloads when publishing tasks over SNS and SQS we will base64 encode the payload and store the encoded payload in DynamoDB.
Add the following to api-stack/api-function/app/dynamo.py.
...import base64import jsonfrom uuid import uuid4from datetime import datetime
...
def create_task(task_type: str, payload: dict) -> str: task_id = str(uuid4()) table.put_item( Item={ "id": task_id, "task_type": task_type, "status": "CREATED", "payload": _encode(payload), "created_time": _get_timestamp(), } )
return {"id": task_id}
def _encode(data: dict) -> str: json_string = json.dumps(data) return base64.b64encode(json_string.encode("utf-8")).decode("utf-8")
def _get_timestamp() -> int: return int(datetime.utcnow().timestamp())And finally, add the following to api-stack/api-function/app/__init__.py.
@app.post("/tasks", status_code=201, response_model=models.CreateResponse)def post_task(payload: models.CreatePayload): return dynamo.create_task(payload.task_type, payload.data)Here we can see how FastAPI takes care of input validation and serialization when we specify the response_model=models.CreateResponse as well as the expected request payload with payload: models.CreatePayload.
Let’s deploy and try creating a task.
$ curl -X POST \ -H "Content-Type: application/json" \ -d '{"task_type": "TASK1", "data": {"foo": "bar"}}' \ https://YOUR_API_URL/tasks{ "id": "12345678-abcd-1234-abcd-112233445566"}
...
$ curl https://YOUR_API_URL/tasks/12345678-abcd-1234-abcd-112233445566{ "id": "12345678-abcd-1234-abcd-112233445566", "task_type": "TASK1", "status": "CREATED", "status_msg": "", "created_time": 1648229203, "updated_time": null}Did you accidentally forgot to copy the task ID after creating a few tasks? If there only was a way to list all tasks without opening up the DynamoDB console. Let’s implement that next.
GET /tasks
The list route will be very simple, without any filter or sort queries. We will allow a maximum of 10 tasks to be returned at a time. If there are more than 10 tasks, we will return a next_token in the response. The next request should then include the next_token in the query string to fetch the next 10 tasks. If there are no more tasks left, next_token will be null.
Since all items in the DynamoDB table have unique primary keys, we will need to use the scan operation to fetch items.
Let’s start with the model for the response which will be a list of tasks and a next_token field.
In api-stack/api-function/app/models.py, add the following.
class TaskListResponse(BaseModel): tasks: list[TaskResponse] next_token: str = NoneMoving on the the actual database logic, we will need to conditionally add the next_token to the scan operation in case it is provided. The next_token will be base64 encoded before it is returned to the client, so we will need to decode it before we can use it.
The scan response will include a LastEvaluatedKey if there are more items left to fetch, so we use that to set the next_token.
Add the following to api-stack/api-function/app/dynamo.py.
def list_tasks(next_token: str = None) -> dict: scan_args = { "Limit": 10, }
if next_token: scan_args["ExclusiveStartKey"] = _decode(next_token)
res = table.scan(**scan_args) response = {"tasks": res["Items"]}
if "LastEvaluatedKey" in res: response["next_token"] = _encode(res["LastEvaluatedKey"])
return response
...
def _decode(data: str) -> dict: json_string = base64.b64decode(data.encode("utf-8")).decode("utf-8") return json.loads(json_string)Finally, add the following to api-stack/api-function/app/__init__.py.
@app.get("/tasks", response_model=models.TaskListResponse)def list_tasks(next_token: str = None): return dynamo.list_tasks(next_token)Now deploy, and you should be able to list all tasks you’ve created.
$ curl https://YOUR_API_URL/tasks{ "tasks": [ { "id": "12345678-abcd-1234-abcd-112233445566", "task_type": "TASK1", "status": "CREATED", "status_msg": "", "created_time": 1648229203, "updated_time": null }, ... more tasks ... ], "next_token": null}We can now create and list tasks, but what good is that if we cannot update their status? Let’s go ahead and implement the final route.
PATCH /tasks/{id}
Tip
This endpoint is supposed to be used internally by the task handlers. Thus, it would be preferable to add some kind of authorization here so that users cannot update tasks directly. But, to keep the scope small, I have ignored it for now.
We want task handlers to be able to update the status of the tasks they handle, as well as an optional message string. Add the following model to api-stack/api-function/app/models.py.
class UpdatePayload(BaseModel): status: status_types status_msg: str = ""The logic for updating a task will be a bit more complex than the other operations. First, we need to make sure the task actually exists. We also want to guard ourselves against multiple handlers trying to start the same task. This could for example happen due to a side effect of the SQS at least once delivery mechanism, or if the visiblity timeout on the queue is shorter than the time it takes to process a task. These two checks are made with conditional updates in DynamoDB.
Add the following code to api-stack/api-function/app/dynamo.py.
from boto3.dynamodb.conditions import And, Attr
...
class InvalidTaskStateError(Error): pass
...
def update_task(task_id: str, status: str, status_msg: str): cond = Attr("id").exists()
if status == "IN_PROGRESS": cond = And(cond, Attr("status").eq("CREATED"))
try: table.update_item( Key={ "id": task_id, }, UpdateExpression="set #S=:s, status_msg=:m, updated_time=:t", # status is reserved ExpressionAttributeNames={ "#S": "status", }, ExpressionAttributeValues={ ":s": status, ":m": status_msg, ":t": _get_timestamp(), }, ConditionExpression=cond, ) except table.meta.client.exceptions.ConditionalCheckFailedException: raise InvalidTaskStateErrorWe first create a condition that requires the item to exist already. Then, if we are setting the state to IN_PROGRESS, we will also require the task to have the status CREATED. This way, if another requests comes in that tries to set the state to IN_PROGRESS while it already is in progress, the request will fail.
We then use the update_item method which will throw an exception if the condition evaluates to false. As far as I know, you cannot see which part of the condition failed, so we cannot differentiate between a task that doesn’t exist and a task that is already in progress.
Finally, add the route to api-stack/api-function/app/__init__.py and we should be good to go.
@app.patch("/tasks/{task_id}", status_code=204)def update_task(task_id: str, payload: models.UpdatePayload): try: return dynamo.update_task(task_id, payload.status, payload.status_msg) except dynamo.InvalidTaskStateError: raise HTTPException( status_code=400, detail="Task does not exist or is already in progress." )Deploy and try it out! You are now finished with the API.
5. DynamoDB Stream
We now want to enable a Stream on the DynamoDB table. I choose to use streams to remove the need to handle transactions. Imagine the following scenario:
- User creates a task through the API
- Task is created in DynamoDB
- Request to SNS fails for some reason
We would then need to roll back the task we created in DynamoDB. By using streams, we make sure that we only send a task to SNS after it has been commited to the database. And, if the request to SNS then fails, the function can be configured to retry a set amount of times.
To enable the stream, add StreamSpecification under properties in the Table resource in the SAM template.
Table: Type: AWS::DynamoDB::Table Properties: ... StreamSpecification: StreamViewType: NEW_IMAGEFor now, we only care about the current state of the items in the stream. If we wanted to act on specific changes in the DynamoDB table, such as send a notification somewhere when a task went from IN_PROGRESS to FAILED, we would need to use NEW_AND_OLD_IMAGES instead of NEW_IMAGE. That way we could compare the old and new values of the item in the stream handler.
6. SNS Topic
We also need an SNS Topic to send our tasks to. Add the following to the SAM template.
Topic: Type: AWS::SNS::Topic
TopicArnParameter: Type: AWS::SSM::Parameter Properties: Name: '/tasks/topic_arn' Type: String Value: !Ref TopicThe resource TopicArnParameter will output the Topic ARN to AWS Systems Manager Parameter Store. This will be used as input to the task handler stack(s).
7. Publisher Lambda
It is time to create our second Lambda function. This function will be responsible for publishing the task to SNS.
Required packages
Add the following to api-stack/publish-function/requirements.txt.
boto3aws-lambda-powertoolsTip
Lambda Powertools for Python is a package that provides a lot of useful features when working with Lambda functions, such as logging, tracing, and data classes for common event source payloads.
SAM Template
Let’s define the publisher function in the SAM template.
PublishFunction: Type: AWS::Serverless::Function Properties: FunctionName: 'TaskPublisher' MemorySize: 128 CodeUri: publish-function Handler: app.handler Runtime: python3.9 Policies: - SNSPublishMessagePolicy: TopicName: !GetAtt Topic.TopicName Environment: Variables: TOPIC_ARN: !Ref Topic Events: Stream: Type: DynamoDB Properties: Stream: !GetAtt Table.StreamArn StartingPosition: TRIM_HORIZON MaximumRetryAttempts: 5 FilterCriteria: Filters: - Pattern: '{"eventName": ["INSERT"]}'Here we can see that we are doing almost the same thing with the SNS Topic as we did with the DynamoDB table in the API function. We are using the built in SNSPublishMessagePolicy policy to give the function permissions to publish to the topic.
We also define a Stream event that will trigger the function when some operation is done in the DynamoDB table. We also define a filter criteria to only trigger the function when a new item is added to the table, i.e. when a task is first created.
Handler
The publisher handler will be quite simple. Here we utilize the package aws-lambda-powertools to provide us with data classes for the event payloads. For each message received from the stream (which is filtered to only include INSERT events), we publish a message to SNS.
We send the payload (which is already base64 encoded) as the message body, and we add the task ID and task type as message attributes.
All in all, it looks like this. Add it to api-stack/publish-function/app/__init__.py and we are done with the entire API stack.
import osimport boto3from aws_lambda_powertools.utilities.data_classes import ( event_source, DynamoDBStreamEvent,)
topic = boto3.resource("sns").Topic(os.environ["TOPIC_ARN"])
@event_source(data_class=DynamoDBStreamEvent)def handler(event: DynamoDBStreamEvent, _): for record in event.records: task_id = record.dynamodb.keys["id"].get_value task_type = record.dynamodb.new_image["task_type"].get_value payload = record.dynamodb.new_image["payload"].get_value
res = topic.publish( MessageAttributes={ "TaskId": { "DataType": "String", "StringValue": task_id, }, "TaskType": { "DataType": "String", "StringValue": task_type, }, }, Message=payload, )
print(f"Message {res['MessageId']} published.")Great job so far! We have now finished the API part of the system, and it is time to start building our handlers.
Build the Handler stack(s)
With the API complete, we can now build the handler stack(s). In this example, I will only create a single stack with a single handler for events with task_type set to TASK1. Implementing handlers for TASK2 and TASK3, or other events, is left as an exercise for the reader.
The stack we will build will include the following resources:
- A Lambda Function that will be responsible for handling the task.
- An SQS Queue that will be used as a middleware between the SNS Topic and Lambda function.
- An SQS Queue Policy that will be used to grant the SNS Topic permission to send messages to the SQS Queue.
- An SNS Subscription between the SNS Topic and the SQS Queue.
- Another SQS Queue that will act as a dead letter queue.
1. Create folder structure and required SAM files
To make it easier to understand in which file everything below should go into, this is how the Handler stack directory will look when you are finished with this section.
handler-stack/ task1-function/ requirements.txt app/ __init__.py template.yml samconfig.tomlAs before, add some boilerplate to the handler-stack/template.yml file.
AWSTemplateFormatVersion: '2010-09-09'Transform: AWS::Serverless-2016-10-31Description: Task API
Resources:We will also use a handler-stack/samconfig.toml file for easier CLI usage.
version = 0.1
[default.global.parameters]stack_name = "TaskHandlers" # Or choose your own stack name
[default.deploy][default.deploy.parameters]capabilities = "CAPABILITY_IAM"s3_bucket = "BUCKET_NAME" # A bucket your credentials have access tos3_prefix = "task-handlers" # The prefix that will be used for your s3 assetsregion = "eu-west-1" # Change to your preferred region2. SQS Queue
First, let’s create the SQS Queue as well as the dead letter queue. Add the following resources to the SAM template.
TaskHandler1Queue: Type: AWS::SQS::Queue Properties: RedrivePolicy: deadLetterTargetArn: !GetAtt TaskHandler1DLQ.Arn maxReceiveCount: 1
TaskHandler1DLQ: Type: AWS::SQS::QueueBy using a DLQ, we will be able to capture events that failed to be processed by the Lambda function. We can analyze the events and either discard them or send them back to the main queue to be processed again. maxReceiveCount specifies how many times you want to retry the event in case of failure before sending it to the dead letter queue. In this example, we will keep it at one to disable retries.
3. SNS Subscription
We now want to set up a subscription to the SNS Topic that was created in the API stack. Remember how we created an SSM parameter in the API stack with the topic arn? We will now import that value in the handler stack. We will also need to create a Queue Policy that will allow the SNS Topic to send messages to the SQS Queue. In the handler we are creating now, we only want to process events which have the message attribute TaskType set to TASK1. To do this, we will use a filter policy on the subscription.
In the SAM template, first add the Parameters section.
Parameters: TasksTopic: Type: AWS::SSM::Parameter::Value<String> Description: Tasks Topic Arn Default: /tasks/topic_arnNow, under resources, add the following.
TaskHandler1QueuePolicy: Type: AWS::SQS::QueuePolicy Properties: Queues: - !Ref TaskHandler1Queue PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: sqs:SendMessage Resource: !GetAtt TaskHandler1Queue.Arn Principal: Service: 'sns.amazonaws.com' Condition: ArnEquals: aws:SourceArn: !Ref TasksTopic
TaskHandler1Subscription: Type: AWS::SNS::Subscription Properties: Protocol: sqs TopicArn: !Ref TasksTopic Endpoint: !GetAtt TaskHandler1Queue.Arn RawMessageDelivery: True FilterPolicy: TaskType: - 'TASK1'4. Handler function
SAM Template
We need to define our Lambda function in the SAM template. Add the following resource.
TaskHandler1Function: Type: AWS::Serverless::Function Properties: FunctionName: 'TaskHandler1' MemorySize: 128 Timeout: 30 CodeUri: task1-function Handler: app.handler Runtime: python3.9 Policies: - SQSPollerPolicy: QueueName: !GetAtt TaskHandler1Queue.QueueName Environment: Variables: TASKS_API_URL: !Ref TasksApiUrl Events: Stream: Type: SQS Properties: Queue: !GetAtt TaskHandler1Queue.Arn BatchSize: 1As you can see, the lambda function requires the URL of the Task API. Since we exported the URL to the parameter store from the API stack, we should add the following under the Parameters section.
TasksApiUrl: Type: AWS::SSM::Parameter::Value<String> Description: Tasks Default: /tasks/api_urlCode
Now it is time to implement the actual task handler for the TASK1 events. The example I will show here is very minimal (and completely useless), but it should be enough to get you started. Again, we will use the aws-lambda-powertools to deserialize the event payload from SQS to make our life a little easier. For each record that the lambda receives, we will do the following.
- Read Task ID and Task Type from the message attributes.
- Decode the base64 encoded payload that the client provided when creating the task.
- Call the Update endpoint in the Task API to set the task to
IN_PROGRESS. - Perform the actual task. In this case, sleep for 10 seconds…
- If the task was successful, call the Update endpoint in the Task API to set the task to
COMPLETED. If an exception was raised, update the status toFAILED.
In the code example, I also randomly raise exceptions to simulate failures.
All in all, the handler function looks like this. Add it to the handler-stack/task1-function/app/__init__.py file.
import base64import jsonimport osimport timeimport requestsimport randomfrom aws_lambda_powertools.utilities.data_classes import ( event_source, SQSEvent,)
API_URL = os.environ["TASKS_API_URL"]
@event_source(data_class=SQSEvent)def handler(event: SQSEvent, context): for record in event.records: task_id = record.message_attributes["TaskId"].string_value task_type = record.message_attributes["TaskType"].string_value payload = _decode_payload(record.body)
print(f"Starting task {task_type} with id {task_id}") _update_task_status(task_id, "IN_PROGRESS", "Task started") try: _do_task(payload) except Exception as e: print(f"Task with id {task_id} failed: {str(e)}") _update_task_status(task_id, "FAILED", str(e)) continue
print(f"Task with id {task_id} completed successfully.") _update_task_status(task_id, "COMPLETED", "Task completed")
def _do_task(payload: dict): # Do something here. print(f"Payload: {payload}") time.sleep(10) if random.randint(1, 4) == 1: # Simulate failure in some invocations raise Exception("Task failed somehow")
def _decode_payload(payload: str) -> dict: json_string = base64.b64decode(payload.encode("utf-8")).decode("utf-8") return json.loads(json_string)
def _update_task_status(task_id: str, status: str, status_msg: str): data = { "status": status, "status_msg": status_msg, }
url = f"{API_URL}/tasks/{task_id}" res = requests.patch(url, json=data)
if res.status_code != 204: print(f"Request to API failed: {res.json()}") raise Exception("Update task status failed")Also, don’t forget the to add the required packages in the handler-stack/task1-function/requirements.txt file.
aws-lambda-powertoolsrequestsThe handler stack is done for now, I’ll leave you to implement the actual task and perhaps create handlers for the other task types as well. Time to deploy what we have so far!
Showtime
It’s showtime. With both stacks deployed, try creating a few tasks through the API and see the magic happen. Try creating both tasks with Task Type TASK1 and TASK2 and see what happens. If everything works as it’s supposed to, you should see the TASK1 tasks change status to IN_PROGRESS and then COMPLETED/FAILED after a few seconds. Tasks with other task types should be ignored and be left with status CREATED.
# Create a task with type TASK1$ curl -X POST \ -H "Content-Type: application/json" \ -d '{"task_type": "TASK1", "data": {"foo": "bar"}}' \ https://YOUR_API_URL/tasks{ "id": "11111111-abcd-1111-abcd-111111111111"}
# Create a task with type TASK2$ curl -X POST \ -H "Content-Type: application/json" \ -d '{"task_type": "TASK2", "data": {"foo": "bar"}}' \ https://YOUR_API_URL/tasks{ "id": "22222222-abcd-2222-abcd-222222222222"}
# List tasks. The task with type TASK1 should have status IN_PROGRESS and the other# should still have status CREATED. If it isn't IN_PROGRESS, try again after a few seconds.$ curl https://YOUR_API_URL/tasks{ "tasks": [ { "id": "11111111-abcd-1111-abcd-111111111111", "task_type": "TASK1", "status": "IN_PROGRESS", "status_msg": "", "created_time": 1648229203, "updated_time": null }, { "id": "22222222-abcd-2222-abcd-222222222222", "task_type": "TASK1", "status": "CREATED", "status_msg": "", "created_time": 1648229203, "updated_time": null }, ], "next_token": null}
# Allow 10 seconds for the task to complete and then list tasks again. The task should# now have the status COMPLETED or FAILED.$ curl https://YOUR_API_URL/tasks{ "tasks": [ { "id": "11111111-abcd-1111-abcd-111111111111", "task_type": "TASK1", "status": "COMPLETED", "status_msg": "", "created_time": 1648229203, "updated_time": 1648229218 }, { "id": "22222222-abcd-2222-abcd-222222222222", "task_type": "TASK1", "status": "CREATED", "status_msg": "", "created_time": 1648229203, "updated_time": null }, ], "next_token": null}Cleaning up
To remove everything we have created, simply run the sam delete command in the api-stack and handler-stack directories.
Potential improvements
While this is a simple example, there are many things we could do to make it better. Below are some ideas that I can think of from the top of my head. Why don’t give one of them a try?
Authentication and Authorization
Right now there is no authentication or authorization on the Task API. This means that any client can create tasks and see the status of any task, and also update the status of tasks. First, I would make sure that only the handlers themselves are allowed to use the PATCH /tasks/{id} endpoint. This could for example be done by setting up IAM authorization on the API Gateway. Secondly, we might want to require that the client is authenticated before creating and listing tasks. If you want to do this in a serverless fashion, you could look into AWS Cognito and use a JWT authorizer.
DynamoDB TTL
Since our list endpoint retrieves all tasks, this list could grow very large. Perhaps we want to remove tasks when they are older than a certain amount of time. This could be done by setting a TTL on the DynamoDB table to automatically delete old tasks after a set period of time.
Logging
Right now we do not have much logging in place. And in the few places we have, it is only simple print statements that aren’t as structured as we want. aws-lambda-powertools has a great logging library that helps with setting up structured logs for your lambda functions.
Tracing
Monitoring in distributed serverless systems can be quite daunting. AWS provides X-Ray for this purpose, which is a distributed tracing system. This can help you visualize the flow of events in your application going from the API Gateway -> Lambda -> DynamoDB -> Lambda -> SNS -> SQS -> Lambda and so on. aws-lambda-powertools has a great tracer library that helps with setting up X-Ray for your lambda functions.
Error handling
I have not included any kind of error handling in the example. You could for example implement functionality to allow a task to be retried a set amount of times in case of failure. Right now, if a task fails, it will be updated in Dynamo to have a status of FAILED. The current implementation of the update endpoint requires the task to be have a status of CREATED when updating the status to IN_PROGRESS. If that logic is left unchanged, retried invocations will fail on the first request to the update endpoint.
Webhooks
Most of the improvements above have been about securing, managing, and monitoring the API. We could also extend it with new features. One example would be to include webhooks. Clients could for example include a webhook URL in their task creation request. We could then add another lambda function that reads from the DynamoDB stream and sends a notification to the webhook URL when the task goes from IN_PROGRESS to COMPLETED or from IN_PROGRESS to FAILED.
To be able to react on certain changes in a DynamoDB item, you must update the stream view type to be NEW_AND_OLD_IMAGES instead of NEW_IMAGE. This way the lambda will receive both the old and the new version of the item.
Scoped events
Perhaps you want to scope tasks to users, applications, or some other entity in your system. Then, I would do the following changes.
- Change the DynamoDB schema to use both a HASH key and SORT key, and set the HASH key to be the entity ID and SORT key to be the task ID.
- Change the API to include the entity ID in the request, such as
POST /{entity_id}/tasks. - Update the boto3 DynamoDB client calls to use the correct key. The scan operation would for example be replaced with a query operation, using the Entity ID as the query key.
Conclusion
Congratulations for making it this far. You have now managed to build an asynchronous task API running entirely on serverless services on AWS. Hopefully you have learned a thing or two, I know I definitely did by creating this. If you have any questions, please feel free to reach out to me in any way you see fit.
All code in this guide is available on GitHub. It might drift a bit if I decide to build upon it, but if I do, I will try to keep this blog entry up to date.
Now go build something awesome! Why not try implementing one of the ideas from the potential improvements section?